机器之心专栏
机器之心编辑部
位置编码技术是一种能够让神经网络建模句子中Token位置信息的技术。在Transformer大行其道的时代,由于Attention结构无法建模每个token的位置信息,位置编码(Positionembedding)成为Transformer非常重要的一个组件。研究人员也提出了各种各样的位置编码方案来让网络建模位置信息,Rope和Alibi是目前最被广泛采纳的两种位置编码方案。
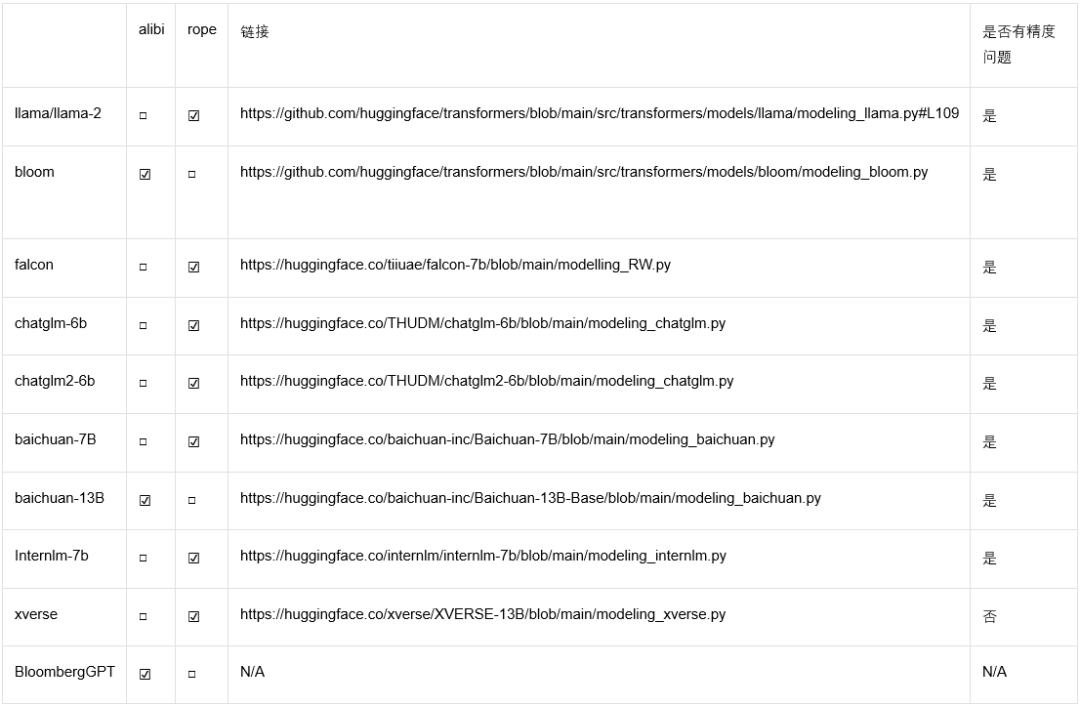
然而最近来自百川智能的研究发现,Rope和alibi位置编码的主流实现在低精度(尤其是bfloat16)下存在位置编码碰撞的bug,这可能会影响模型的训练和推理。而且目前大部分主流开源模型的实现都存在该问题,连llama官方代码也中招了。
还得从位置编码算法说起
为了弄清楚这个问题,得先从位置编码的算法原理说起,在Transformer结构中,所有AttentionBlock的输入都会先经过位置编码,再输入网络进行后续处理。纯粹的Attention结构是无法精确感知到每个token的位置信息的,而对于语言的很多任务来说,语句的顺序对语义信息的影响是非常大的,为了建模token之间的位置关系,Transfomer原始论文中引入位置编码来建模位置信息。
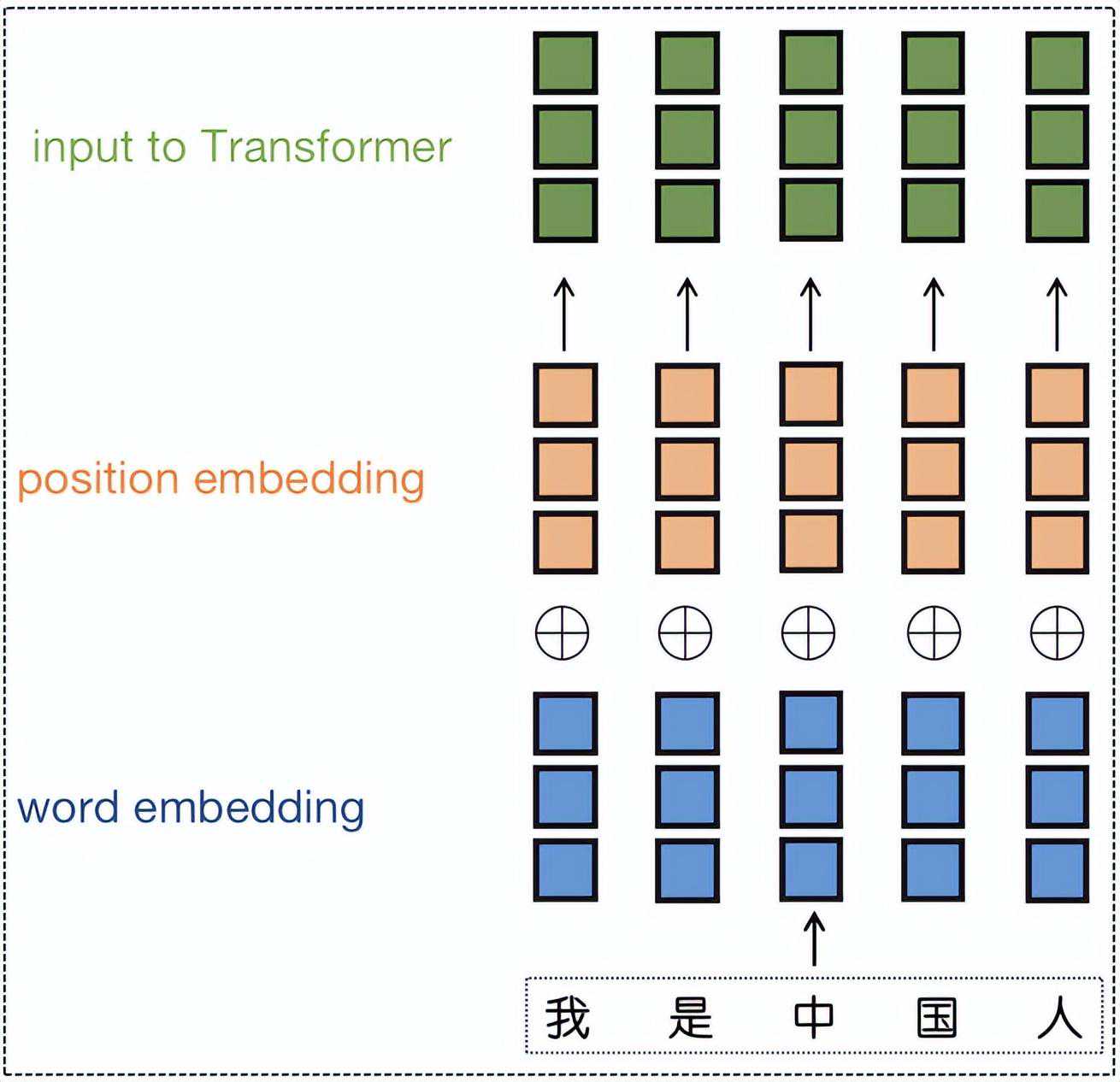
图1-施加PositonEmbedding示意图。
为了让模型更好地建模句子的位置信息,研究人员提出了多种位置编码方案,meta开源的llama[4]模型采用了Rope[5]方案,使得Rope成为在开源社区被广泛采纳的一种位置编码方案。而Alibi编码因其良好的外推性也被广泛应用。
了解低精度下的位置编码碰撞之前,先来回顾一下相关算法原理。
Sinusoidal位置编码
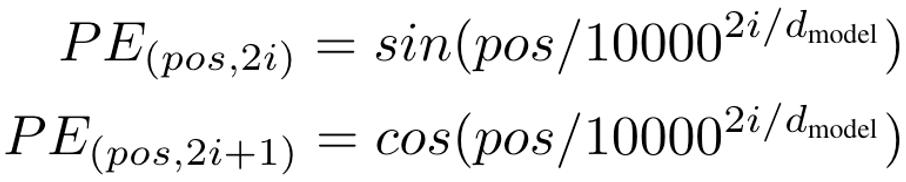
这是Transformer原始论文中提出的位置编码方法。它通过使用不同频率的正弦和余弦函数来为每个位置产生一个独特的编码。选择三角函数来生成位置编码有两个良好的性质:
1)编码相对位置信息,数学上可以证明PE(pos+k)可以被PE(pos)线性表示,这意味着位置编码中蕴含了相对位置信息。
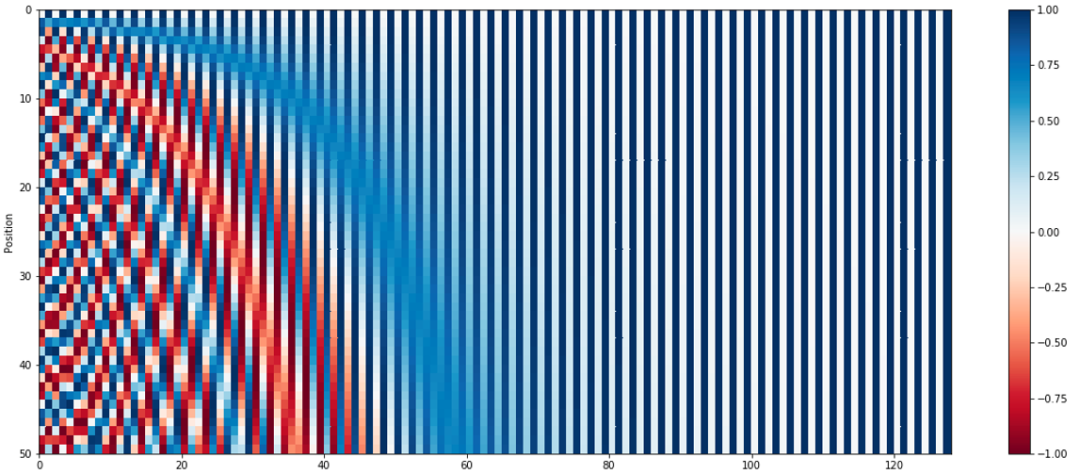
图2-句子长度为50的位置编码,编码维度128,每行代表一个PositionEmbedding。
2)远程衰减:不同位置的positionencoding点乘结果会随着相对位置的增加而递减[1]。
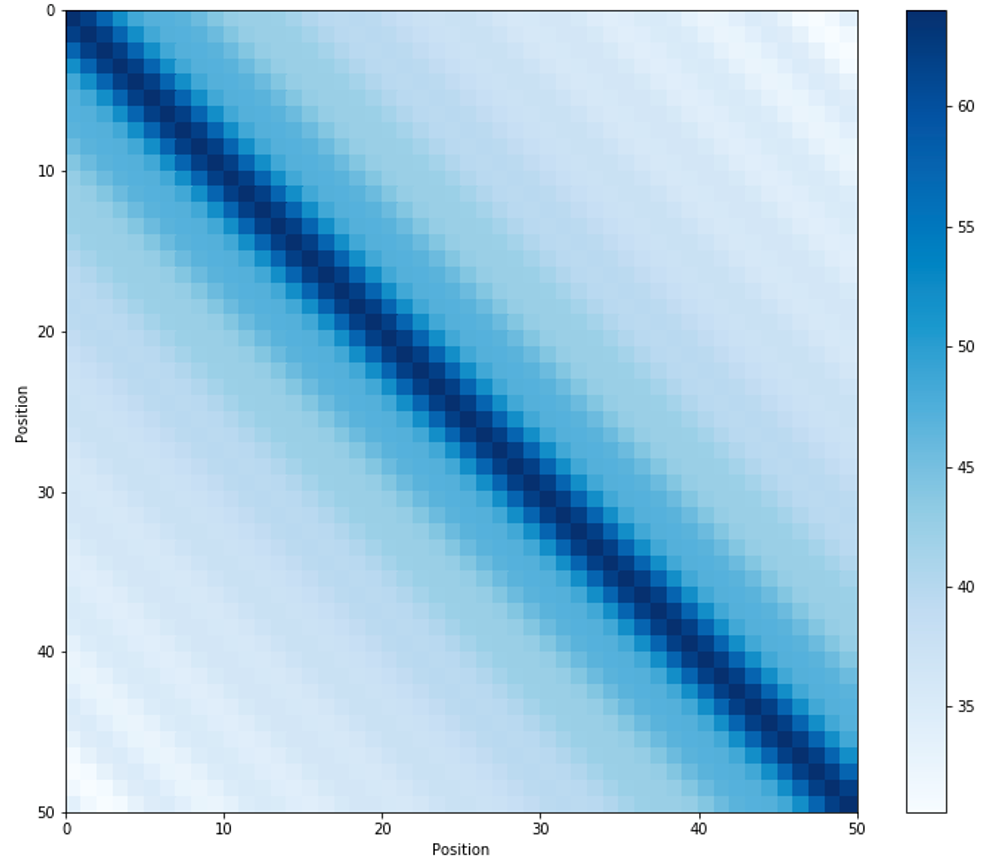
图3-不同位置的位置编码点积可视化。
Rope
Rope是目前开源社区应用最广泛的一种位置编码方案,通过绝对位置编码的方式实现相对位置编码,在引入相对位置信息的同时保持了绝对位置编码的优势(不需要像相对位置编码一样去操作attentionmatrix)。令f_q,f_k为位置编码的函数,m表示位置,x_m表示该位置token对应的embedding,我们希望经过位置编码后的embedding点积仅和相对位置有关,则可以有公式:
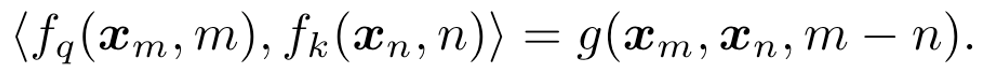
上面公式中g是某个函数,表示内积的结果只和x_m和x_n的值,以及二者位置的相对关系(m-n)有关在2维的情况下可以推导出(详细推导过程可参考原论文):
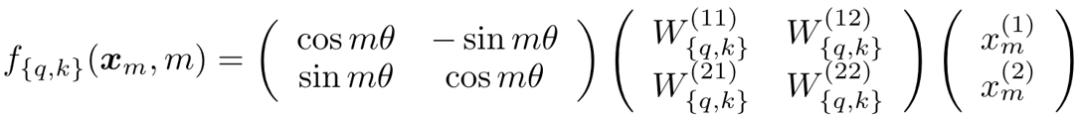
因为矩阵乘法线性累加的性质,可以拓展到多维的情况可得:
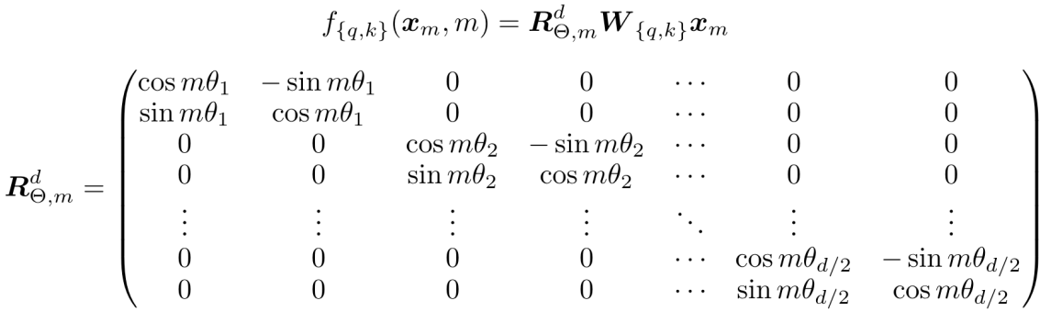
为了引入远程衰减的特性,Rope中\theta的选取选择了Transformer原始论文中sinusoidal公式。
Alibi
Alibi是谷歌发表在ICLR2022的一篇工作,Alibi主要解决了位置编码外推效果差的痛点,算法思想非常的简单,而且非常直观。与直接加在embedding上的绝对位置编码不同,Alibi的思想是在attentionmatrix上施加一个与距离成正比的惩罚偏置,惩罚偏置随着相对距离的增加而增加。在具体实现时,对于每个head会有一个超参m来控制惩罚偏置随着相对距离增加的幅度(斜率)。
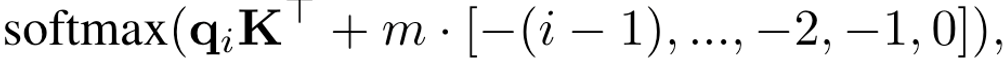
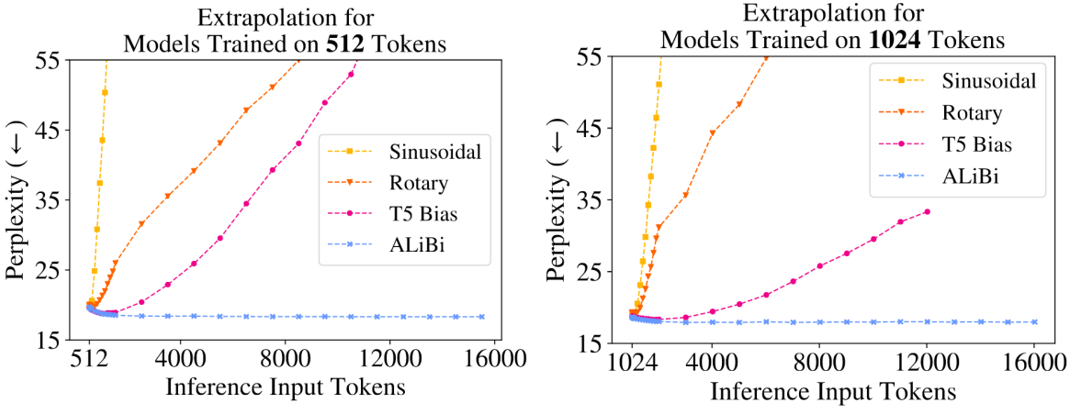
图4-Alibiattentionbias示意图
论文结果显示Alibi极大的提升了模型的外推性能,16ktoken的输入依然可以很好的支持。
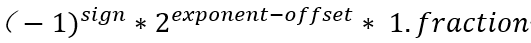
图5-Alibi外推效果对比。
混合精度下位置编码的bug
从上面的算法原理中,不管是rope的cos(m\theta)还是alibi的i-1(m,i代表postionid),需要为每个位置生成一个整型的position_id,在上下文窗口比较大的时候,百川智能发现目前主流的位置编码实现在混合精度下都存在因为低精度(float16/bfloat16)浮点数表示精度不足导致位置编码碰撞的问题。尤其当模型训练(推理)时上下文长度越来越长,低精度表示带来的位置编码碰撞问题越来越严重,进而影响模型的效果,下面以bfloat16为例来说明这个bug。
浮点数表示精度
浮点数在计算机中表示由符号位(sign),指数位(exponent),尾数位(fraction)三部分组成,对于一个常规的数值表示,可以由如下公式来计算其代表的数值(其中offset是指数位的偏置):
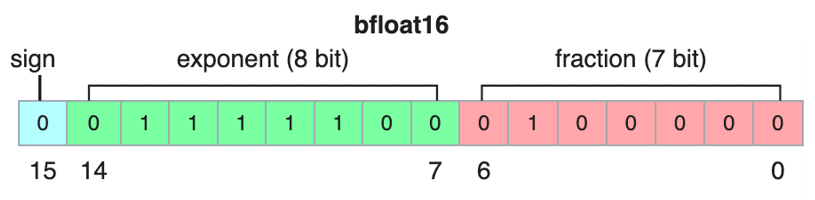
由公式可知,尾数位的长度决定了浮点数的表示精度。深度学习中常用的float32/float16/bfloat16内存中的表示分别如下图所示:
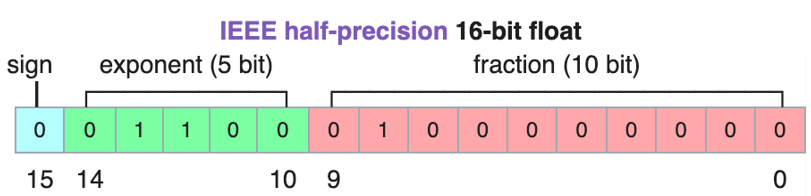
图6-bfloat16的表示格式

图7-float16的表示格式
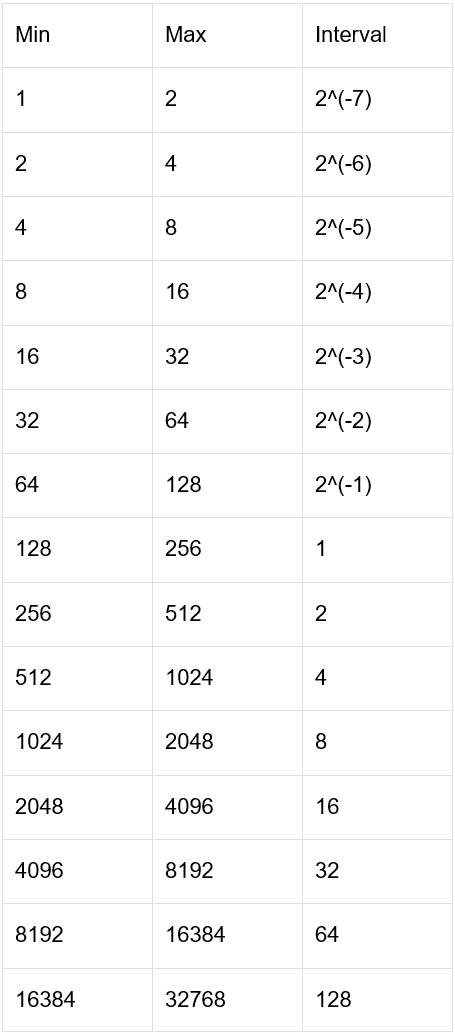
图8-float32的表示格式
可以看到float16和bfloat16相比于float32都牺牲了表示的精度,后续以bfloat16为例说明位置编码中存在的问题(float16同理)。下表展示了bfloat16在不同数值范围(只截取整数部分)内的表示精度。
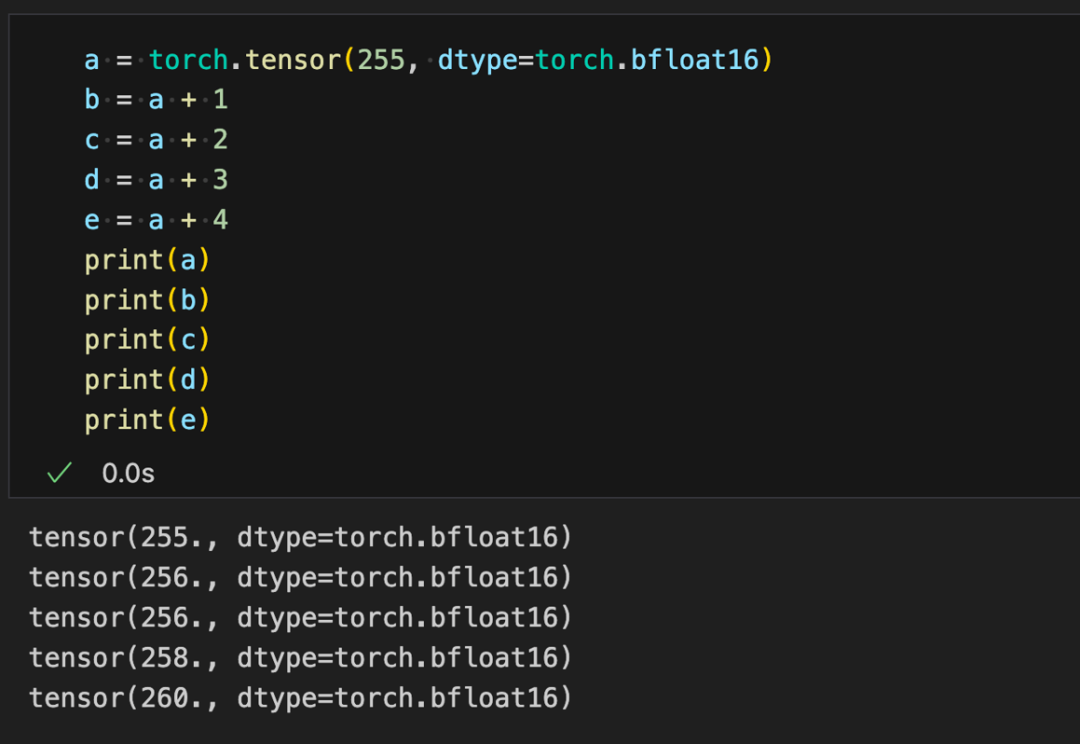
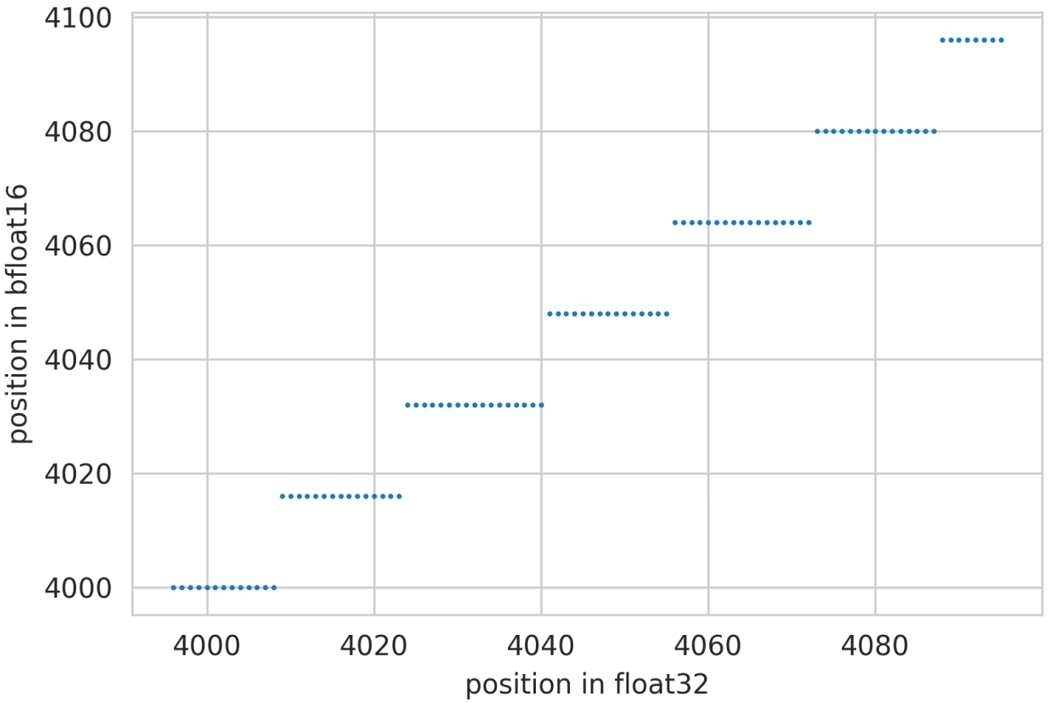
可以看到当整数范围超过256,bfloat16就无法精确表示每一个整数,可以用代码验证一下表示精度带来的问题。
RopeAlibi编码的问题
Meta开源的llama模型采用了Rope的位置编码方式,官方的实现(以及大部分的第三方llama系列模型)在bfloat16下存在精度问题带来的位置编码碰撞(不同位置的token在bfloat16下变成同一个数)。Llama官方代码如下:
PythonclassLlamaRotaryEmbedding():def__init__(self,dim,max_position_embeddings=2048,base=10000,device=None):super().__init__()=_position_embeddings=max_position_=baseinv_freq=1.0/(**((0,,2).float().to(device)/))_buffer("inv_freq",inv_freq,persistent=False)Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculationemb=((freqs,freqs),dim=-1)_buffer("cos_cached",()[None,None,:,:].to(dtype),persistent=False)_buffer("sin_cached",()[None,None,:,:].to(dtype),persistent=False)defforward(self,x,seq_len=None):_===(_seq_len_cached,device=device,dtype=_)在实际训练时如果开了bfloat16,_freq的dtype会被转为bfloat16,可以通过简单的代码来看一下位置碰撞的问题。
Pythont=(4096,dtype=)(t[-100:],t[-100:].to().float(),s=0.8)('positioninfloat32')('positioninbfloat16'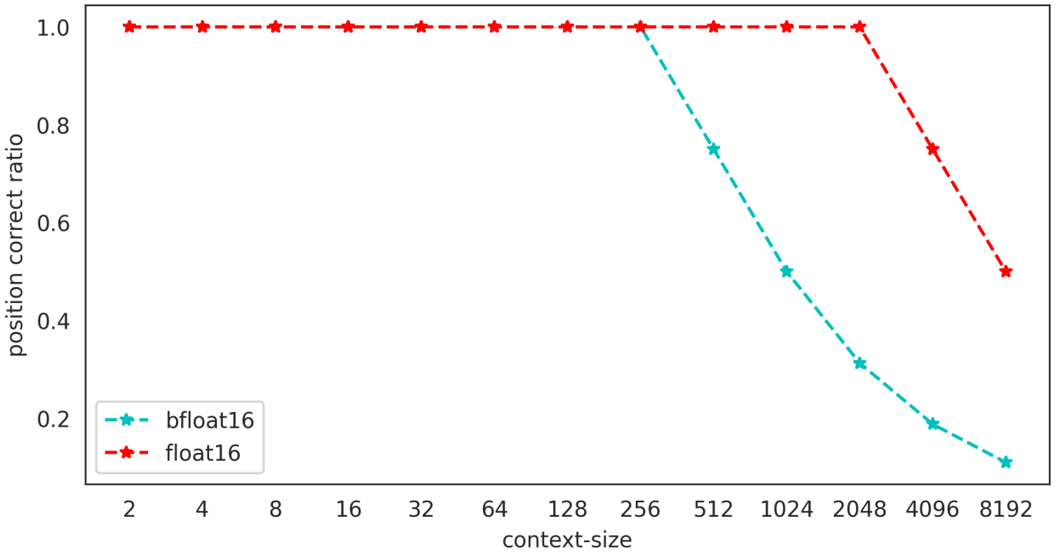
根据bfloa16的表示精度可知,训练(推理)时上下文长度越长,位置编码碰撞的情况越严重,长度为8192的上下文推理中,仅有大约10%的token位置编码是精确的,好在位置编码碰撞有局域性的特质,只有若干个相邻的token才会共享同一个positionEmbedding,在更大的尺度上,不同位置的token还是有一定的区分性。
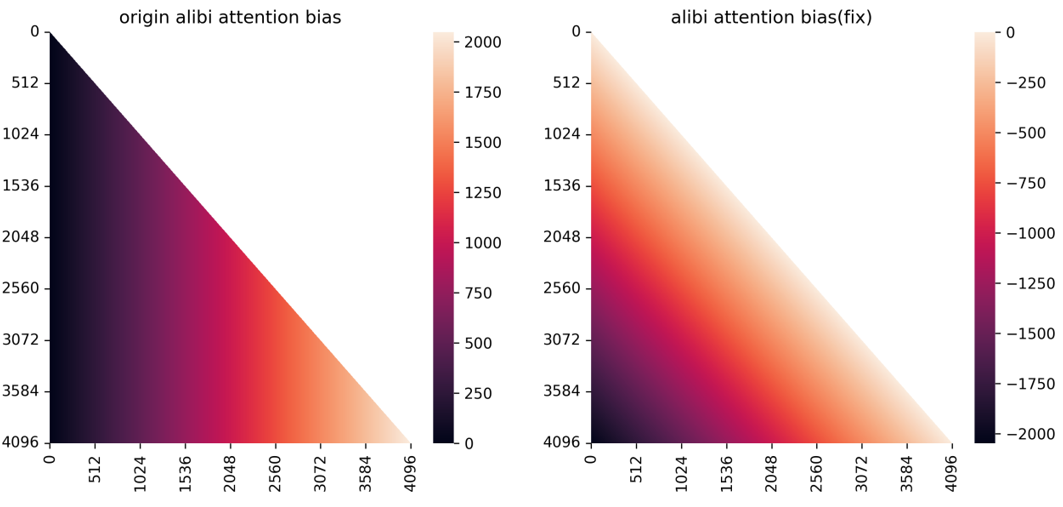
图10-不同上下文窗口下位置编码精确token所占比例。
除了llama模型,百川智能发现alibi位置编码也存在上述问题,原因依然在于生成整数的位置索引时会在低精度下产生碰撞问题。
修复方案
Rope修复
Rope的修复相对简单,只需要保证在生成position_id的时候一定在float32的精度上即可。注意:
float32的tensorregister_buffer后在训练时如果开启了bfloat16,也会被转为bfloat16。
PythonclassLlamaRotaryEmbedding():def__init__(self,dim,max_position_embeddings=2048,base=10000,device=None):super().__init__()=_position_embeddings=max_position_=_freq=1.0/(**((0,,2).float().to(device)/))Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculationemb=((freqs,freqs),dim=-1)_buffer("cos_cached",()[None,None,:,:],persistent=False)_buffer("sin_cached",()[None,None,:,:],persistent=False)defforward(self,x,seq_len=None):#x:[bs,num_attention_heads,seq_len,head_size]ifseq__seq_len_cached:self._set_cos_sin_cache(seq_len=seq_len,device=,dtype=)return(_cached[:,:,:seq_len,].to(dtype=),_cached[:,:,:seq_len,].to(dtype=),)Alibi修复
alibi位置编码修复思路和Rope的修复思路一致,但因为alibi的attentionbias直接加在attentionmatrix上面,如果按照上面的修复思路,attentionmatrix的类型必须和attentionbias一致,导致整个attention的计算都在float32类型上计算,这会极大的拖慢训练速度
目前主流的attention加速方法flashattention不支持attentionbias参数,而xformers要求attentionbias类型必须与相同,因此像rope那样简单的将attentionbias类型提升到float32将会极大的拖慢训练速度
针对该问题百川智能提出了一种新的alibiattention方案,整个attentionbias依然在bfloat16类型上,类似于sinusiodal的远程衰减特质,可以尽量保证临近token位置编码的精确性,对于相对距离过远的的token则可以容忍其产生一定的位置碰撞。原本的alibi实现则相反,相对距离越远的token表示越精确,相对距离越近的token则会碰撞
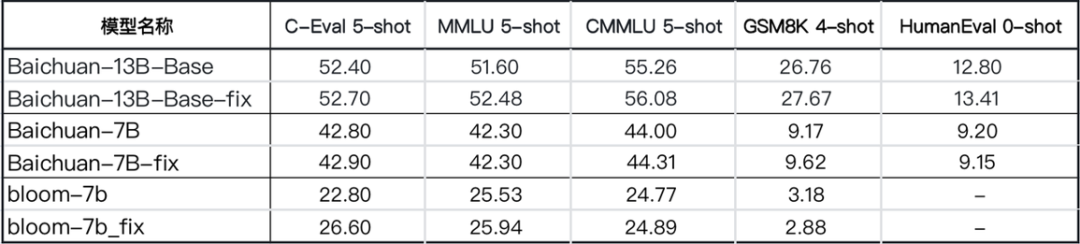
图11-修复前后alibiattention_bias对照。
修复效果
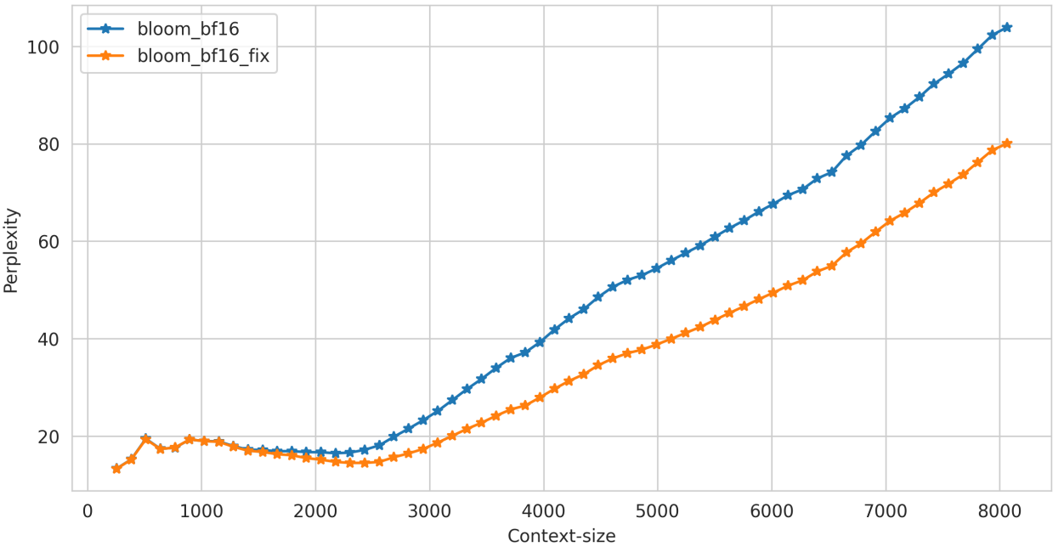
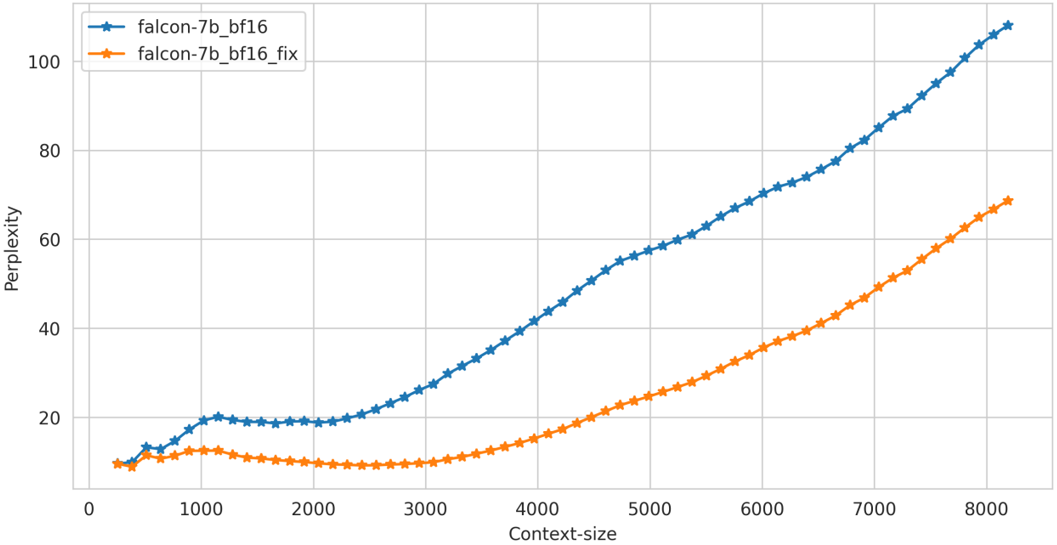
百川智能仅在推理阶段对位置编码的精度问题进行修复【注:训练阶段可能也存在问题,取决于训练的具体配置和方法】,可以看到:
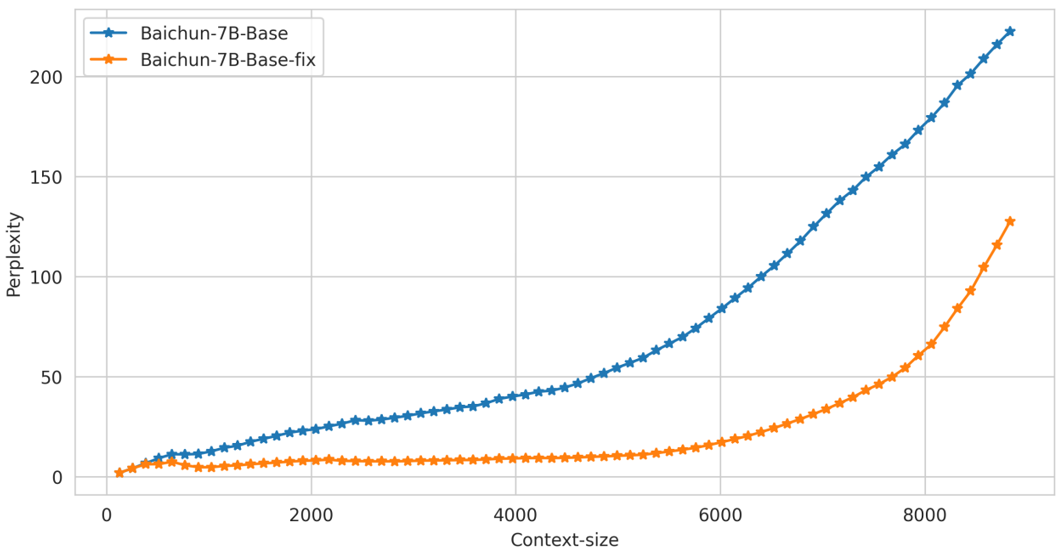
a.在长上下文的推理中,模型的ppl要显著优于修复前的ppl
上测试结果显示修复前后区别不大,可能是因为benchmark上测试文本长度有限,很少触发Positionembedding的碰撞
Benchmark对比
Perplexity
我们在通用的文本数据上对修改前后模型在中英文文本上的困惑度进行测试,效果如下:

[0]DongxuZhang,DongWang.(2015).RelationClassificationviaRecurrentNeuralNetwork.
[1]AshishVaswani,NoamShazeer,NikiParmar,JakobUszkoreit,LlionJones,,LukaszKaiser,IlliaPolosukhin.(2023).AttentionIsAllYouNeed.
[2]ZihangDai,ZhilinYang,YimingYang,JaimeCarbonell,,RuslanSalakhutdinov.(2019).Transformer-XL:AttentiveLanguageModelsBeyondaFixed-LengthContext.
[3]ColinRaffel,NoamShazeer,AdamRoberts,KatherineLee,SharanNarang,MichaelMatena,YanqiZhou,WeiLi,(2020).ExploringtheLimitsofTransferLearningwithaUnifiedText-to-TextTransformer.
[4]HugoTouvron,ThibautLavril,GautierIzacard,XavierMartinet,Marie-AnneLachaux,TimothéeLacroix,BaptisteRozière,NamanGoyal,EricHambro,FaisalAzhar,AurelienRodriguez,ArmandJoulin,EdouardGrave,GuillaumeLample.(2023).LLaMA:OpenandEfficientFoundationLanguageModels.
[5]JianlinSu,YuLu,ShengfengPan,AhmedMurtadha,BoWen,YunfengLiu.(2022).RoFormer:EnhancedTransformerwithRotaryPositionEmbedding.
[6]OfirPress,,MikeLewis.(2022).TrainShort,TestLong:AttentionwithLinearBiasesEnablesInputLengthExtrapolation.
[7]YutaoSun,LiDong,BarunPatra,ShumingMa,ShaohanHuang,AlonBenhaim,VishravChaudhary,XiaSong,FuruWei.(2022).ALength-ExtrapolatableTransformer.
[8]
[9]ShouyuanChen,ShermanWong,LiangjianChen,YuandongTian.(2023).ExtingContextWindowofLargeLanguageModelsviaPositionalInterpolation.
[10]
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系