在传统操作字符串的过程中,我们可能通过for、indexOf、lastIndexOf、trim等来实现具体的功能。比如找出字符串中是否有l,"hello".indexOf("l")-1,但是hello可能是大写HELLO,我们要实现不管大写还是小写时,那么我们需要再增加一串代码才能实现此功能。那么如果使用正则表达式的话,这将非常简单。/[lL]/.test("hello")或者/l/("hello")都可以。
当然正则表达式远不止于此,这只是一个非常简单的例子。
正则表达式主要用于匹配字符串,用它神奇的语法来实现字符串的搜索、替换、过滤、验证文本数据等操作。在不同编程语言及代码中,我们都能看到它的身影。
当然,不同编程语言的正则表达式语法大体是相通的,同时也有一些细微的差别,多多实践就行。
正则表达式包含普通字符和元字符两种类型,通俗一点的说,普通字符就是直接匹配文本中的字符,比如字母、数字、中文和标点符号等等。而元字符(特殊的字符或正则语法字符)则表示有特殊含义,比如.、^、$、*、+、?、\、[]、|等。
下面让我们一步一步的走进正则表达式。
声明方式Javascript的正则表达式的声明一般有两种方式。
1、字面量形式声明,使用两个斜杠来表示。
constreg=/exp/gim
2、字符串形式声明。
constreg=newRegExp('exp','gim');g、i、m为可选参数,分别代表全局匹配、不区分大小写、多行匹配。可以根据实际情况添加使用。
基础用法1、字符匹配
使用普通字符匹配文本。例如,找出world,替换为King,并且不区分大小写。
constcontent='HelloWorld!';//斜杠后面加i表示不区分大小写constreg=/world/i;constresult=(reg,'King');(result);//输出:'HelloKing!'
使用.匹配任何单个字符。例如,把hello或hallo换成大写HELLO。
constcontent='Hello、hallo';//斜杠后面加i表示不区分大小写constreg=//i;constresult=(reg,'HELLO');(result);//输出:'HELLO、hallo'//斜杠后面加g表示全局匹配,也就是匹配多次。//不加的话表示只匹配一次。constreg_g=//gi;constresult_g=(reg_g,'HELLO');(result_g);//输出:'HELLO、HELLO'
2、字符集
使用方括号来列出可能的字符。
例如,把所有a、b、c删除,也就是匹配a或者b或者c。
constcontent='a1b1c1a2b2c2a3c3';constreg=/[abc]/g;constresult=(reg,'');(result);//输出:'11122233'
例如,删除所有的小写字符字母。
constcontent='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';//[a-z]表示a-z所有26个字母,//相当于[abcdefghijklmnopqrstuvwxyz]的简写。//如果还需要删除大写字母,在斜杠后面添加i即可。constreg=/[a-z]/g;constresult=(reg,'');(result);//输出:'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
例如,删除所有非字母的字符。
constcontent='abcdABCD123456中文,';//[^a-z]表示非26个字母之外的任何字符。//相当于[^abcdefghijklmnopqrstuvwxyz]的简写。constreg=/[^a-z]/gi;constresult=(reg,'');(result);//输出:'abcdABCD'
当然您可以根据实际情况,写出您需要的表达式。
比如:
所有数字:[\d]或者[0-9]。\d是一种元字符类别,可以用于匹配任何数字字符,包括Unicode整数、全角数字等,[0-9]只能匹配ASCII数字字符0到9。可以根据实际情况选择哪一种。
任何单词字符:\w。\w相当于[a-zA-Z0-9_],也就是a-z、A-Z、0-9以及下划线_
所有汉字字符:[\u4e00-\u9fa5]。\u4e00和\u9fa5是Unicode码点,分别对应中文编码范围的起始和结束字符。当然,一些较为生僻的汉字,或者不同文化的汉字可能不在其中,一般情况下已经够用了。
所有已知的汉字:
[\u4E00-\u9FFF\u3400-\u4DBF\uF900-\uFAFF\U00020000-\U0002EBEF]
不要惊讶,这个字符范围包括[\u4E00-\u9FFF]、[\u3400-\u4DBF]、[\uF900-\uFAFF]以及[\U00020000-\U0002EBEF],覆盖了CJK(中、日、韩)和CJK扩展区的所有汉字,并且也包含了一些较为罕见的汉字和方言汉字。这个范围应该已经可以完整匹配目前已知的汉字了。
根据实际情况选择即可。
3、量词
量词表示指定前面的字符或字符集出现的次数。
常见的量词包括:
“+”:出现一次或多次。
“*”:出现零次或多次。
“?”:出现零次或一次。
“{n}”:刚好出现n次。
“{n,}”:出现至少n次。
“{n,m}”:出现n到m次之间。
例如:
匹配多个l。[l]+等价于[l]{1,}。
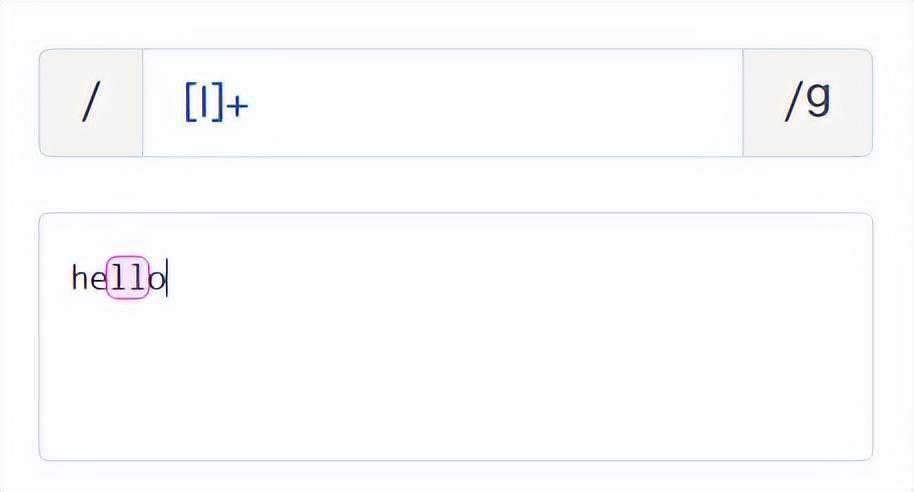
[l]{1,}
4、描点
锚点用于匹配文本的位置,而不是字符本身。
常见的锚点包括:
“^”:匹配文本的开头。
“$”:匹配文本的结尾。
“\b”:匹配单词边界。
“\B”:匹配非单词边界。
例如:/^hello/,匹配以hello开头的字符串。/hello$/,匹配以hello结尾的字符串。
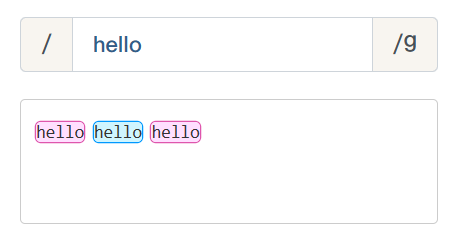
/hello/g
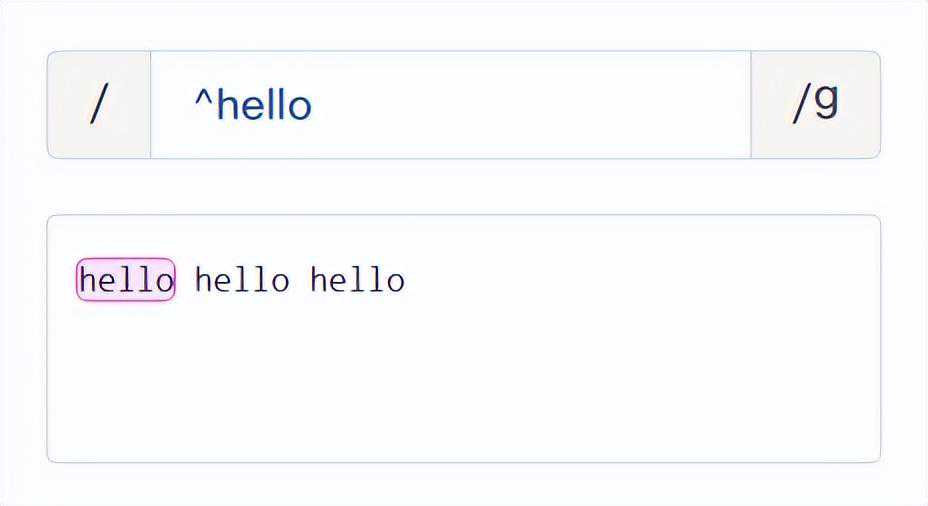
/^hello/
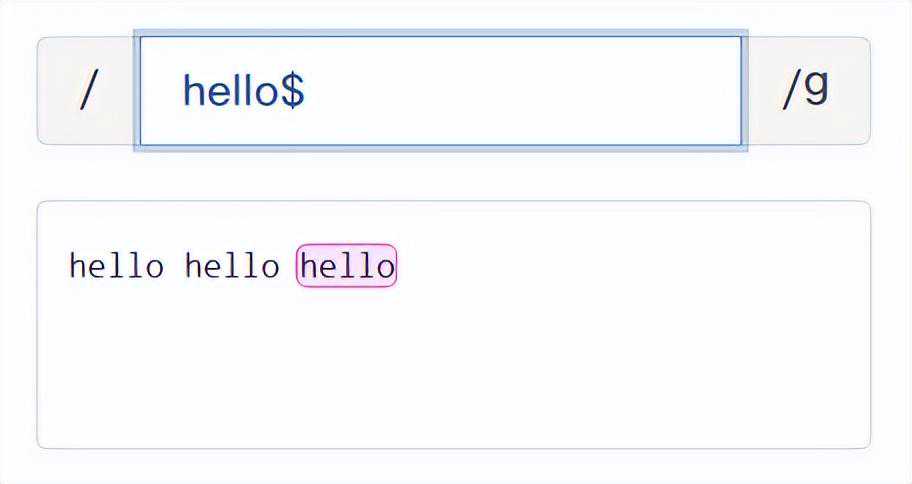
1、分组
分组可以将正则表达式中的模式组合在一起。
括号“()”用于创建组。创建的组可以用于重复、替换等操作。
比如:获取字符串prvt_site-123中的prvt_site与123。
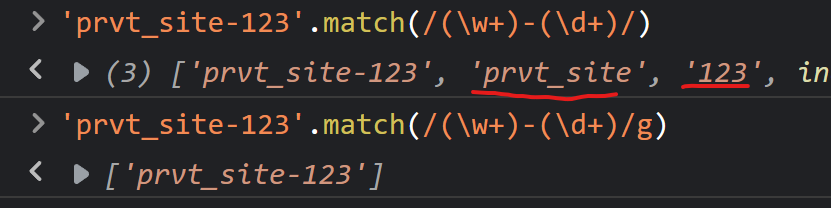
2、向后引用
向后引用允许你在正则表达式中引用先前创建的组。
可以使用反斜杠“\n”(其中n是组号)来引用组。
比如:查找简单的闭合HTML标签。提取标签名及标签内的文本。
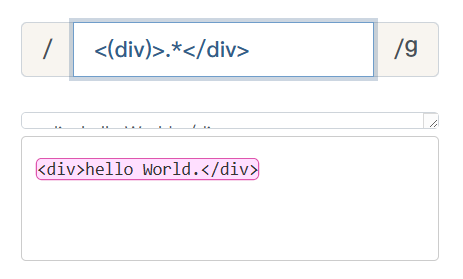
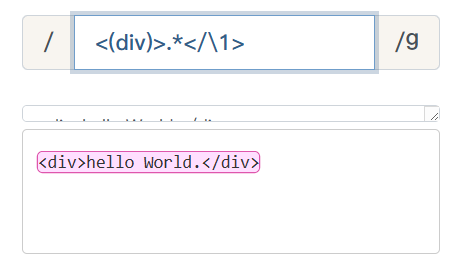
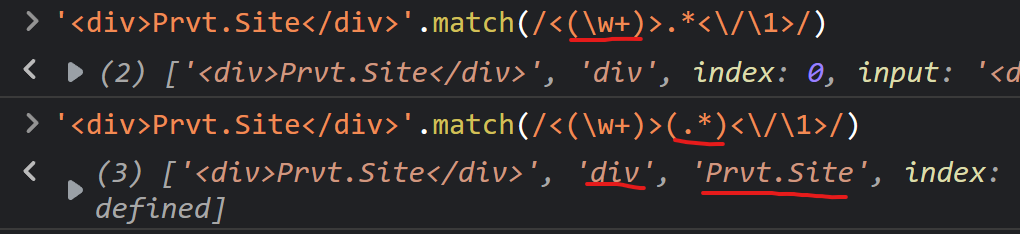
3、前瞻和后顾:
前瞻和后顾允许你查找只在特定模式前面或后面的文本。
语法为“?=”(正向前瞻)、“?!”(负向前瞻)、“?=”(正向后顾)和“?!”(负向后顾)。
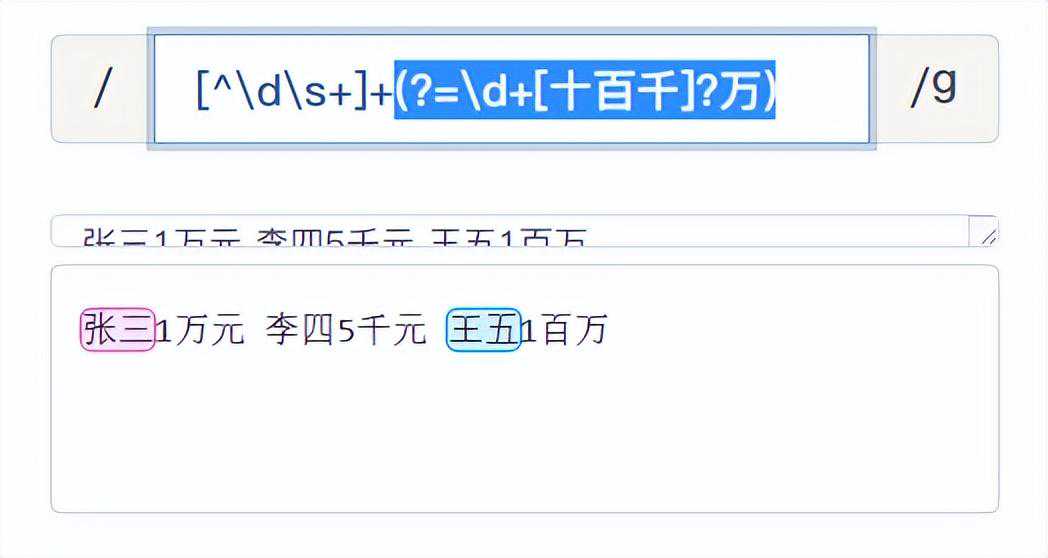
例如:获取收入万元以上的用户。
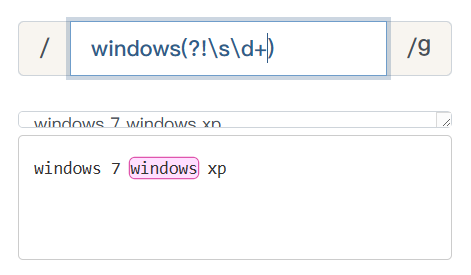
例如:获取非数字版本操作系统前面的windows。
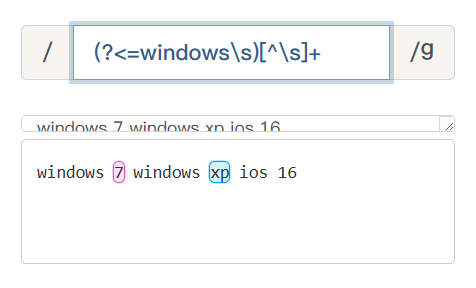
例如:获取所有windows的版本号。
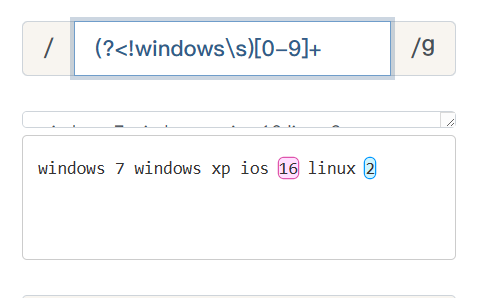
例如:获取所有非windows后面的版本号
4、正则表达式模式修饰符
修饰符用于更改正则表达式的默认行为。
常见的修饰符包括:
“i”:忽略大小写。
“g”:全局匹配。
“m”:多行匹配。
上面示例中,您可能已经了解了修饰符的用法,自己动手试试吧!
人人为我,我为人人,欢迎您的浏览,我们一起加油吧。
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系